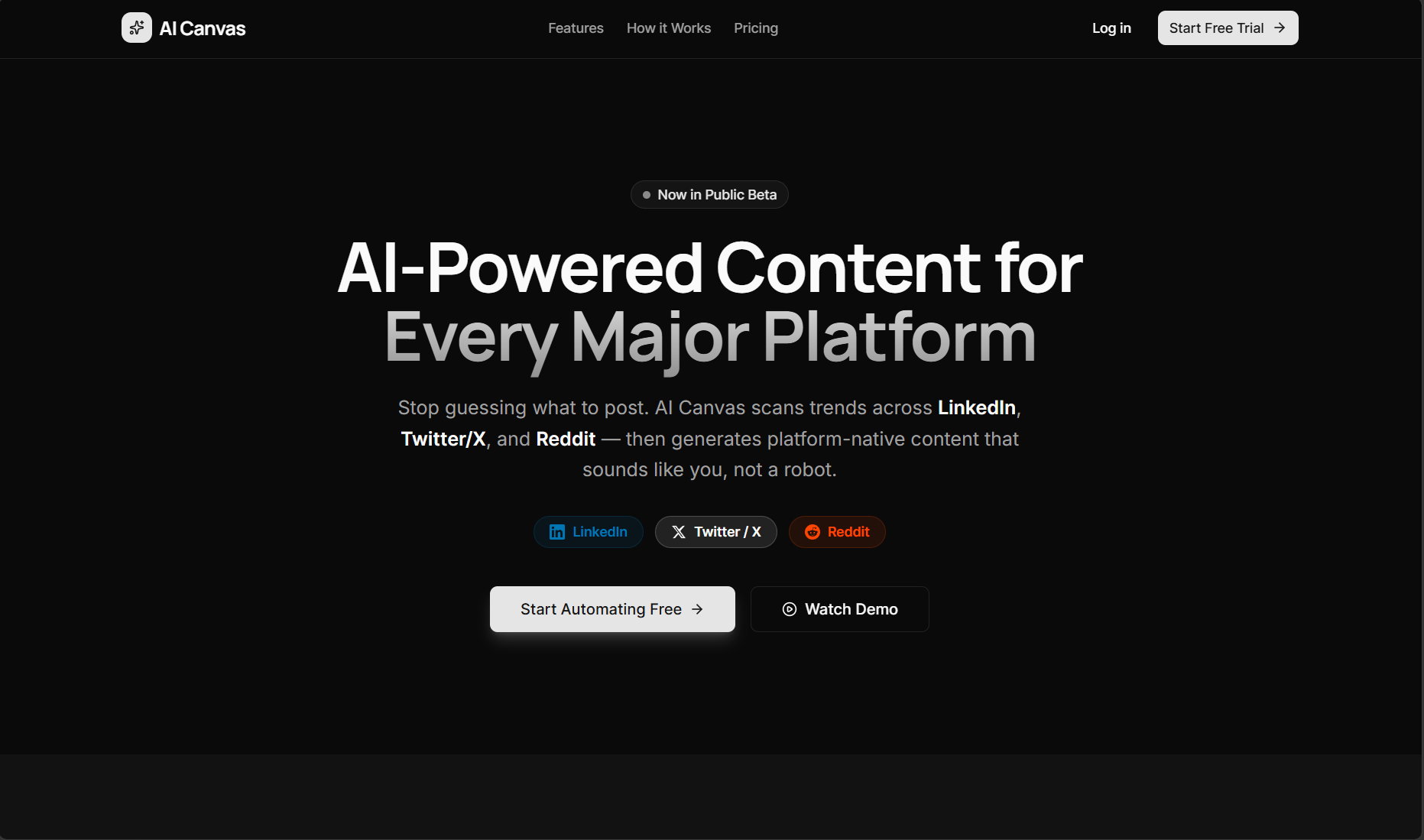
AI-Canvas
Social Media Automation SaaS Platform via Agentic Orchestration
The Problem
Creating high-converting LinkedIn content at scale is extremely manual. Generic LLM wrappers fail because they lack brand voice adaptation, multi-step critique, and intent-aware reasoning.
Why it matters
B2B founders spend 10+ hours a week drafting contextually relevant social content. A deterministic, automated pipeline drastically cuts CAC.
Who is affected
Founders, DevRel Engineers, and SaaS Marketing Teams.
Architecture & System Design
Frontend
Next.js App Router for highly responsive interactive UI with Socket.IO client for live token streaming.
Backend Processing
Node.js environment running LangGraph state machines for deterministic agent routing.
ML Pipeline
LangSmith handles LLM observability and trace abstraction; multiple LLMs deployed specifically via prompt routing.
Architectural Reasoning
Chose LangGraph over CrewAI for highly deterministic logic loops (Critique -> Rewrite) which guarantees content isn't published until it passes a strict internal heuristic.
Alternatives Considered
Standard direct-API calls were considered but quickly led to hallucinated or 'robotic' output. Multi-agent debate was strictly required.
ML & Technical Deep Dive
Model Selection & Training
GPT-4o (Reasoning & Orchestration) + Claude 3.5 Sonnet (Creative Execution)
Zero-shot with heavily engineered system prompts + dynamic few-shot retrieval via RAG context injection.
Dataset
Fine-tuning context windows built upon 500+ top-performing proprietary LinkedIn posts (A/B tested data).
Preprocessing Pipeline
- .01Semantic chunking of previous posts
- .02Vector storage via Pinecone for historical tone retrieval
- .03RAG query expansion
Evaluation Metrics
94%
Generation Coherence<150ms TTFT
Token Streaming Latency85%
Time Saved/PostTechnical Challenges
Core Features
Intent-Aware Generation
Uses user goals, target audience, and context to generate highly specific content.
Real-time Streaming Logs
Socket.IO feeds live agent logic status to the user (e.g. 'Agent analyzing...', 'Critiquing draft...')
Human-in-the-loop (HITL)
Requires manual approval before scheduling, keeping final editorial power with the user.
Results & Impact
Users transitioned from spending 2 hours brainstorming/drafting one post to generating 5 targeted posts in 10 minutes.
Currently actively used by beta users to maintain professional brand presence effortlessly.
80% Content Creation Time Reduction
Sub-150ms TTFT (Time To First Token)
Takeaways & Learnings
What I Learned
Mastered LLM Observability; LangSmith is mandatory for production agentic systems to trace exactly why an agent chose a specific tool.
Trade-Offs Made
Sacrificed minor end-to-end latency to force the LLM to undergo a 'Critique & Refine' sub-graph, increasing quality exponentially.
Future Improvements
Migrate the long-term semantic memory from Pinecone to pgvector for infrastructure consolidation.
Tech Stack Foundation
Frontend
- Next.js
- TailwindCSS
- Framer Motion
Backend
- Node.js
- Socket.IO
- Supabase
ML / AI
- LangChain
- LangGraph
- LangSmith
- OpenAI API
Tools
- Pinecone
- Vercel
Interested in this architecture?
Let's talk about how I can build something similar for your team.